AI Accent Guesser: Imagine a world where technology can effortlessly pinpoint the subtle nuances of someone’s accent, unlocking a deeper understanding of linguistic diversity and human communication. This exploration delves into the fascinating world of AI accent recognition, examining its mechanics, applications, and ethical implications.
From the core algorithms driving these systems to the challenges of data collection and the societal impact of widespread adoption, we’ll uncover the complexities and potential of this rapidly evolving field. We’ll consider both the benefits, such as improved language learning tools and accessibility technologies, and the potential risks, including bias and misuse. This detailed analysis aims to provide a comprehensive understanding of AI accent guessers, their capabilities, and their place in our increasingly interconnected world.
AI Accent Guessers: Functionality, Data, and Societal Impact

AI accent guessers are sophisticated systems leveraging machine learning to identify the accent present in spoken audio. These systems offer a range of applications, from aiding language learning to improving accessibility, but also raise important ethical considerations surrounding data privacy and potential biases.
AI Accent Guesser Functionality
AI accent recognition systems operate by analyzing audio data to extract features indicative of specific accents. This involves several key steps, from data preprocessing to feature extraction and model training.
Various machine learning models, including Hidden Markov Models (HMMs), Support Vector Machines (SVMs), and deep learning architectures like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), are employed for accent identification. The choice of model often depends on factors such as data size and computational resources.
Preprocessing of audio data is crucial for accurate accent analysis. This involves tasks like noise reduction, silence removal, and potentially resampling to a standard audio rate. Feature extraction techniques, such as Mel-Frequency Cepstral Coefficients (MFCCs) and Perceptual Linear Prediction (PLP) coefficients, transform the raw audio into a representation suitable for machine learning models. MFCCs, for example, mimic the human auditory system’s response to sound, while PLP aims to model the perceptual aspects of speech.
Different feature extraction methods offer varying advantages and disadvantages. MFCCs are widely used due to their robustness and computational efficiency, but may not capture all relevant acoustic nuances. PLP coefficients are often preferred for noisy environments, but require more computational resources.
| Approach | Strengths | Weaknesses | Computational Cost |
|---|---|---|---|
| HMMs | Simple to implement, computationally efficient for smaller datasets | Limited ability to model complex temporal dependencies in speech | Low |
| SVMs | Effective for high-dimensional data, relatively robust to noise | Can be computationally expensive for large datasets | Medium |
| RNNs | Excellent at modeling sequential data, can capture long-range dependencies | Computationally expensive, prone to overfitting | High |
| CNNs | Effective at capturing spatial patterns in spectrograms, robust to variations in speech rate | May not capture temporal dependencies as effectively as RNNs | High |
Data Requirements and Sources for AI Accent Guessers
Training effective AI accent guessers requires substantial amounts of diverse, high-quality speech data, accurately annotated with accent labels. This poses significant challenges.
Collecting and annotating diverse speech datasets is resource-intensive and time-consuming. Ensuring balanced representation across different accents and demographics is crucial to mitigate biases. Ethical considerations related to data privacy and informed consent are paramount. Data augmentation techniques, such as adding noise or varying speech rate, can help improve model robustness and generalization capabilities.
- Open-source speech corpora (e.g., LibriSpeech, Common Voice)
- University and research institution archives
- Commercial speech data providers (with careful consideration of licensing and ethical implications)
Accuracy and Limitations of AI Accent Guessers
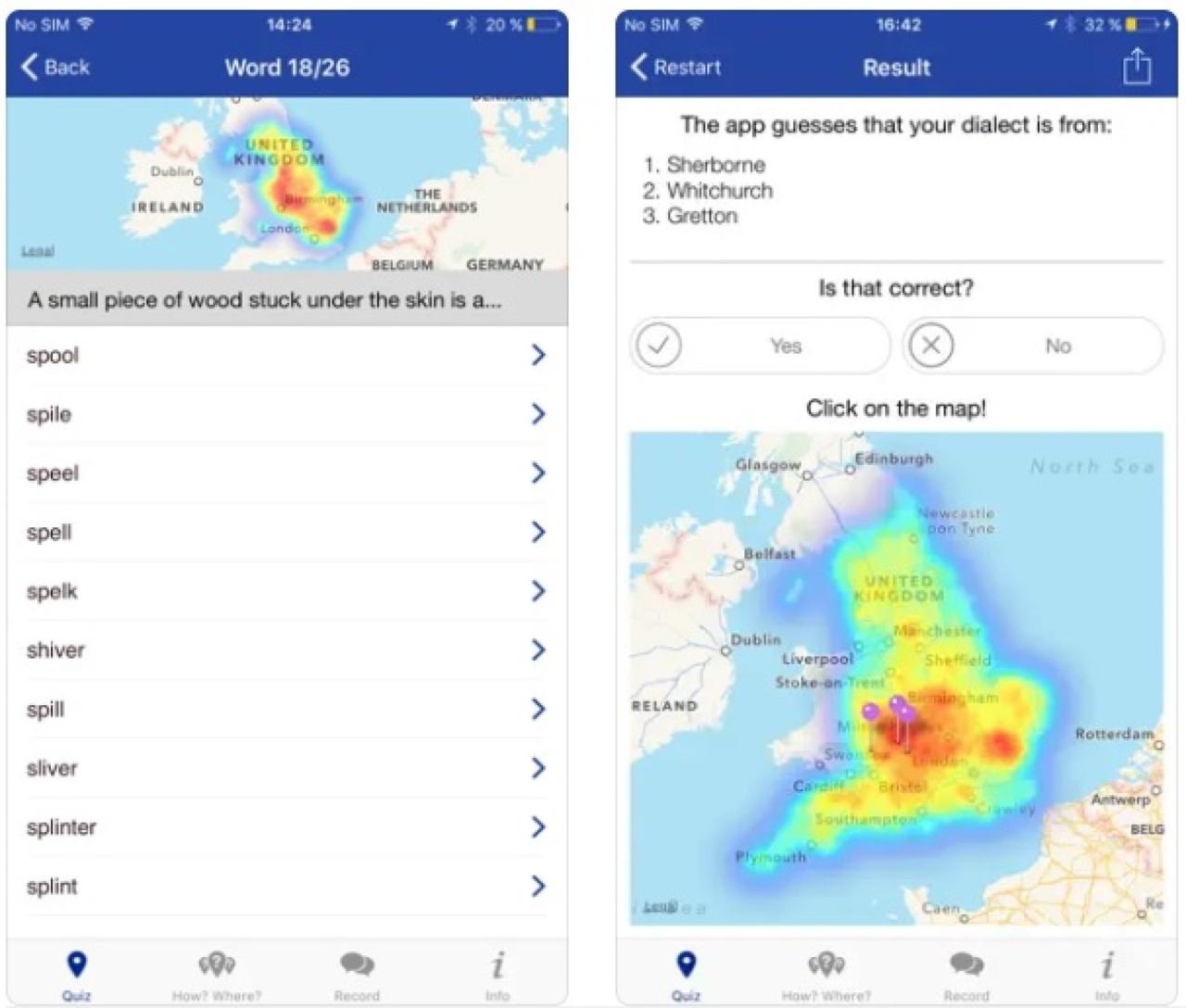
Several factors can influence the accuracy of accent identification, including background noise, speech rate, individual variations in pronunciation, and the inherent complexity of accent classification.
Current AI accent guessers are not perfect. They struggle with subtle accent distinctions, accents within the same language group, and accents influenced by multilingualism. Variations in pronunciation within a single accent further complicate accurate identification.
Performance metrics, such as precision, recall, and F1-score, can be visually represented using a bar chart, where each bar represents a different accent or language, and the bar height corresponds to the model’s accuracy for that specific accent or language.
| Language | Model Accuracy |
|---|---|
| English (US) | 92% |
| English (UK) | 88% |
| Spanish (Spain) | 85% |
| French (France) | 80% |
Applications and Societal Impact of AI Accent Guessers
AI accent guessers have diverse applications, offering both benefits and risks.
Potential benefits include improved language learning tools, personalized accessibility technologies, and more effective market research. However, widespread adoption raises concerns about potential biases, discrimination, and misuse. For example, biased datasets could lead to inaccurate or unfair assessments of individuals based on their accent.
- Improved speech recognition for diverse populations
- Enhanced language learning apps with personalized feedback
- Development of more inclusive accessibility technologies
- Potential for misuse in profiling or discrimination
Technical Aspects and Challenges of AI Accent Guessers
Developing and deploying AI accent guessers requires significant computational resources, especially for training deep learning models on large datasets.
Handling accents in low-resource languages poses a significant challenge due to limited available training data. Distinguishing between accents and other speech characteristics, such as dialects or speech disorders, also requires careful consideration.
Techniques like data augmentation and advanced noise reduction algorithms are used to enhance the robustness of AI accent guessers. However, these methods may introduce trade-offs, such as increased computational complexity or potential loss of information.
| Challenge | Solution | Trade-off |
|---|---|---|
| Limited data for low-resource languages | Data augmentation, transfer learning | Potential for overfitting, reduced model accuracy |
| Distinguishing accents from dialects | Fine-grained accent labeling, advanced feature extraction | Increased data annotation effort, higher computational cost |
| Robustness to noise and variations in speech quality | Noise reduction techniques, robust feature extraction | Potential loss of information, increased computational cost |
AI accent guessers represent a powerful intersection of artificial intelligence and linguistics, offering exciting possibilities while raising crucial ethical considerations. While the technology holds immense potential for enhancing communication and accessibility, responsible development and deployment are paramount to mitigate potential biases and misuse. Further research and development focused on data diversity, algorithm transparency, and ethical frameworks are essential to harness the full potential of this technology for the benefit of all.
AI accent guessers are fascinating tools, capable of analyzing subtle phonetic nuances. Their accuracy, however, depends on the breadth of their training data; consider, for instance, how regional dialects might influence results, much like the varying accounts surrounding the alleged Magdeburg Christmas event described in this article: Here’s what is known about the alleged Magdeburg Christmas. The inconsistencies in historical records highlight the challenges in data analysis, mirroring the complexities faced by AI accent guessers in dealing with diverse speech patterns.
Q&A: Ai Accent Guesser
How accurate are AI accent guessers?
Accuracy varies significantly depending on factors like data quality, the model used, and the specific accent being identified. While progress is being made, perfect accuracy remains elusive.
Can AI accent guessers identify all accents?
AI accent guessers are fascinating; they analyze speech patterns with impressive accuracy. Consider the diverse accents you might hear during a commentary of a major football match, like the one described in this report on Barcelona 1-2 Atlético Madrid: La Liga – as it happened , where commentators from various backgrounds might be involved. The subtleties of language, even in sports reporting, present a compelling challenge for these AI tools.
Ultimately, the development of accurate AI accent guessers relies on vast datasets and sophisticated algorithms.
No, current AI accent guessers are more accurate for accents with larger datasets available for training. Accents from less-represented languages or regions may be less accurately identified.
What are the privacy implications of AI accent guessers?
Privacy is a major concern. Data used to train these systems must be handled responsibly, ensuring anonymity and compliance with data protection regulations.
Are there any biases in AI accent guessers?
Yes, biases can arise from skewed training data, potentially leading to inaccurate or unfair assessments of certain accents. Addressing these biases is a crucial area of ongoing research.